Home>Research>
Research and Outcomes>Voice recognition and audio processing
Voice recognition and audio processing


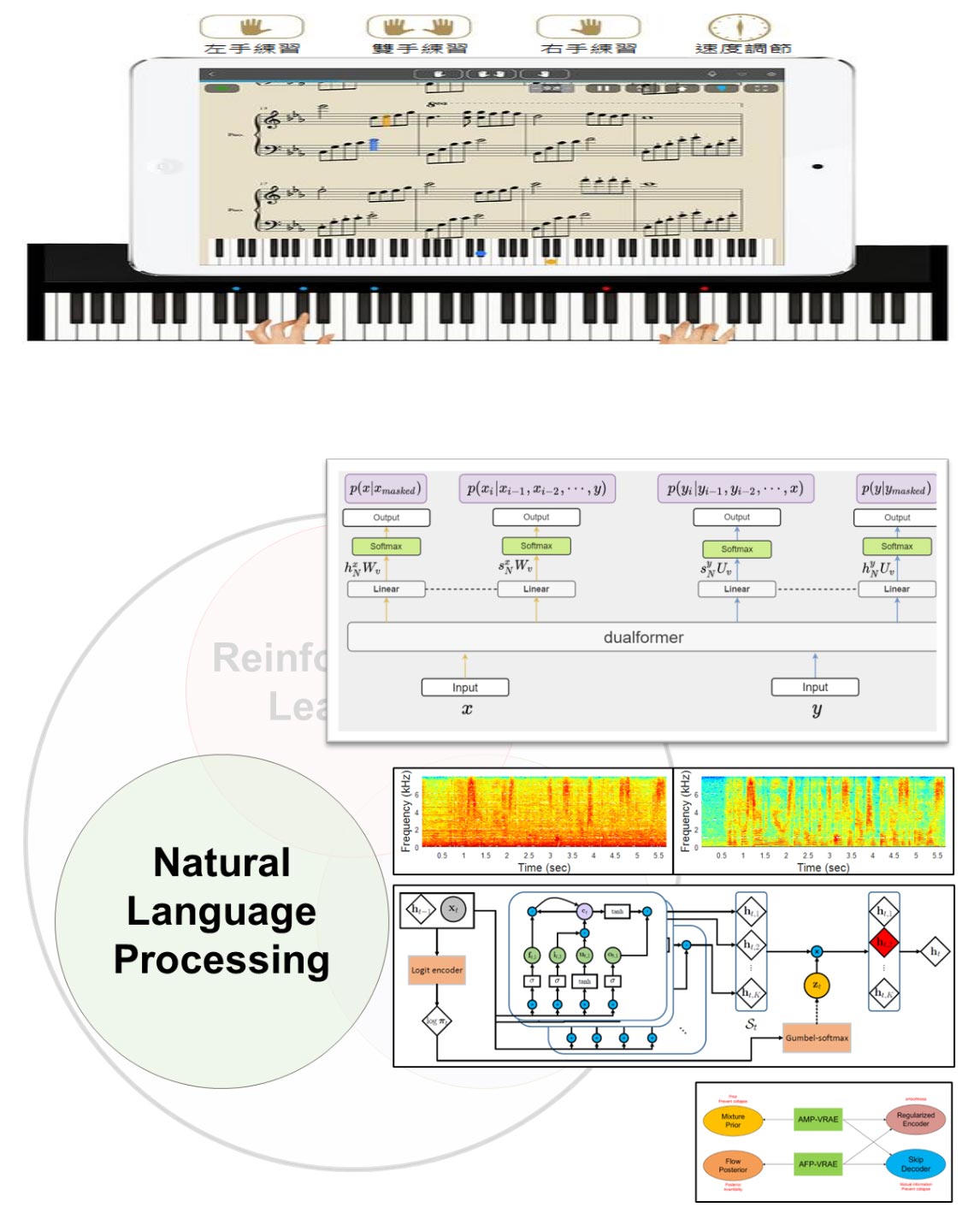
Automatic speech recognition (i.e., computer speech recognition or speech to text) can be applied in voice recognition, speech synthesis, and natural language processing in Mandarin. Similar research has been applied in real-time translation and multilingual database construction. Recent language processing via deep neural networks can translate a language in a more realistic and precise manner, accurately representing different dialects and pronunciations. Moreover, unlike traditional keyword searching, our research teams provide various applications with fast and precise responses based on information retrieval from musical contents. We apply machine learning algorithms to construct an interactive music coaching platform with virtual tutors for users to compose a pieces of music. On the other hand, audio processing techniques are widely applied in many products, such as hearing aids, cochlear implants, and noise-canceling headphones. For audio processing, we include noise canceling and echoing techniques to improve the quality of speech transmission, recognition, and the measurement of speech intelligibility. Nevertheless, audio specialization and soulful music synthesis can be applied to virtual reality and interactive games.